深入理解函数式编程
这句话比较难理解,换句话来说:函数式编程是给自己的对象整容,有可能整的和原来差不多,也有可能整的看起来判若两人,但是只能处理这个对象,不会对函数外的其他数据产生影响。
函数式编程又结合了lambda表达式和stream API。有些朋友反馈说:函数式编程可读性不好;还有些朋友反馈说:函数式编程比较难debug。你们说的都对,但是有解决的办法,看完这篇文章就明白了。
文章整体大纲如下:

lambda表达式
lambda表达式的本质是匿名内部类
先来看一个例子:杜甫的《登高》写的好,被称为千古律诗之首。

我从十几岁的时候开始就一直在想这首诗怎么不押韵:渚清沙白鸟飞回,高中老师讲过古语里“回”念huai,这就压上韵了。但是潦倒新停浊酒杯的杯在古语或者古语方言里念bai吗?直到如今我还是没有考证到是否是这样。我就当它是念bai吧。
这首诗我最喜欢的四句,渲染磅礴的气势都含了数字:万里、百年、无边、不尽。我突发奇想:让电脑来给这四句排排序吧。于是我写了下面的程序:
public void sortDengGao() { List<String> list = Lists.newArrayList("无边落木萧萧下","不尽长江滚滚来","万里悲秋常作客","百年多病独登台"); list.sort(new Comparator<String>() { @Override public int compare(String o1, String o2) { return o1.substring(0, 2).compareTo(o2.substring(0, 2)); } }); System.out.println(list); }我鼠标点在new Comparator上,提示我匿名内部类可以用lambda代替:

使用Alt+Enter快捷键,我回车一下,结果变成了这样:
public void sortDengGao() { List<String> list = Lists.newArrayList("无边落木萧萧下","不尽长江滚滚来","万里悲秋常作客","百年多病独登台"); list.sort((o1, o2) -> o1.substring(0, 2).compareTo(o2.substring(0, 2))); System.out.println(list); }当然还可以再执行一次Alt+Enter还原回来。
匿名内部类和lambda表达式既然可以使用快捷键相互转换,那就说明他们本质上是一个东西。这样就好理解了:在jdk1.8之前,通过匿名内部类访问局部变量必须要加final关键字,jdk1.8之后不需要显示的加final关键字但实际上还是需要被访问的变量不可变。这就对应了函数式编程不会对函数外的其他数据产生影响。
lambda表达式的省略规则
lambda表达式核心是(对于匿名内部类)采用可推导可省略的原则。所以有些朋友反馈说:函数式编程可读性不好。因为它做了省略,如果对原本被省略的匿名内部类不熟悉,阅读就会麻烦些。还有一点哈,编写代码注意换行哈:
list.stream().sorted((o1, o2) -> o1.substring(0, 2).compareTo(o2.substring(0, 2))).close();这段代码一个方法用一行是不是好看一些:
list.stream() .sorted((o1, o2) -> o1.substring(0, 2).compareTo(o2.substring(0, 2))) .close();lambda表达式是对匿名内部类的下面三点做了省略:
-
参数类型可省略
-
方法只有一句代码时:大括号、return和分号可省略
-
方法只有一个参数时小括号可以省略
stream API
stream API就是运用fluent风格的一个特例
对fluent风格不熟悉的强烈建议看看我之前的这篇《代码荣辱观-以运用风格为荣,以随意编码为耻》。这篇文章逻辑清晰,语言诙谐,比喻恰当,专治不明白。
这里只举个简单的例子:StringBuilder一般是这样使用的:
new StringBuilder().append(1).append(2).toString();这是典型的fluent风格。咱们来看它包含几部分:
第一部分:new StringBuffer()构造一个特定对象
第二部分:append()对这个对象本身做处理,可以多次调用,每次都返回它本身
第三部分:toString()结束处理
再来看这个stream API的例子:
list.stream() .sorted((o1, o2) -> o1.substring(0, 2).compareTo(o2.substring(0, 2))) .close();第一部分:.stream()构造一个特定对象
第二部分:sorted()对这个对象本身做处理,可以多次调用,每次都返回它本身
第三部分:close()结束处理
是不是一毛一样!stream API就是运用fluent风格的一个特例,如此而已。所以我们要关注的点只是.stream()构造的特定对象Stream给我提供了怎么的功能,达到了号称比sql还简单、还强大的功能。
一分钟理解MapReduce
MapReduce现在流行于大数据中的概念,本质上是为了解决对于数据的并行计算方法明明本质上都是采用分治法,但是缺少高层并行编程模型,程序员需要自行指定存储、计算、分发等任务的问题。MapReduce借鉴了Lisp函数式语言中的思想,用map和reduce两个函数提供了高层的并发编程模型的抽象。
直白点说就是提供了一个计算手脚架,照着这个架子做开发就可以了。

上面图中可以看到map的主要功能是把数据分成小块进行计算,reduce是将小块计算结果进行合并。在stream API中map和reduce功能也是一样的。举个例子:
public void mapReduceDengGao() { List<String> list = Lists.newArrayList("无边落木萧萧下","不尽长江滚滚来","万里悲秋常作客","百年多病独登台"); String result = list.stream() .map(word->word+"\n") .reduce((a,b)->a+""+b) .get(); System.out.println(result); }上面函数先用map方法把list每个元素都进行了处理:后面加换行符。然后用reduce方法对数据合并计算:合并为一个字符串。大数据的MapReduce也就是干了这!
用Intellij对stream API做debug
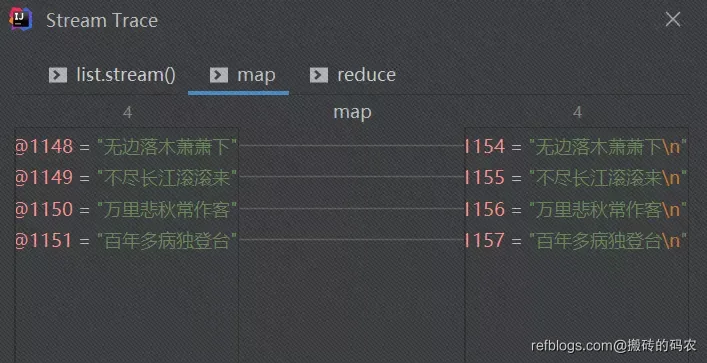
有些朋友反馈说:函数式编程比较难debug。stream trace了解一下。

首先在steam API的地方打上断点。当运行到断点处,点击上面红色框框里那个图标,之后会弹出一个框,但是可能一开始没有数据,提示正在计算,稍等一会之后stream的每一步调用结果都可以看到啦:
总结
函数式编程的优势:
-
代码可读性高
-
大数据量下处理集合效率高
-
消灭嵌套地狱
代码可读性高,上面已经讲过了,因为简洁明了。
大数据量下处理集合效率高,这个主要是指因为函数式编程功能内聚,JVM优化时去掉了多余的锁。像上面MapReduce那段讲的,采用分治法,使用并行流的话内部做了很好的多线程处理。
消灭嵌套地狱嘛,看看下面箭头形代码:

用函数式编程效果是这样的,好看不好看不好说,起码sonar静态检查能过:




