MySQL的undo日志---MVCC前置知识
undo日志
前面学习了redo日志,redo日志保证的是崩溃时事务持久性。我们可以从redo日志恢复到系统崩溃以前。
undo日志就是为了保证事务回滚时事务所作所为都能回到事务执行前。保证了事务的原子性。redo把我们做增删改之前的状态记录下来,帮助MySQL回滚到事务执行之前的样子。
这篇文章了解一下事务ID和undo日志产生就OK了,对于Undo日志存储可以直接略过。
事务ID
事务两种类型:只读事务,读写事务。
针对于只读事务,MySQL会在其对用户创建的临时表进行增删改的时候才会为其分配事务ID,否则不分配。
这里的临时表指的是create temporary 表名,和我们使用explain SQL的时候在extra上显示的using temporary不一样。前者是用户创建的用户临时表,只针对于当前session有效,后者是MySQL内部临时表。
而针对于读写事务来说,MySQL会在事务执行对某个表进行增删改的时候为其分配一个事务ID,否则不分配。
事务ID生成
在系统启动时,系统维护一个全局变量,我们首先从内存中找到MAX TRX ID这个值然后加上256,赋给这个全局变量。
每次出现上述情况的事务时会为其分配一个ID,然后变量进行+1操作。
然后每每这个全局变量是256的倍数时候就会对这个变量进行同步修改到系统表空间中的MAX TRX ID属性处。
然后我们为什么在取值的时候要加上256呢?主要是因为我们系统关闭是可能已经大于当前MAX TRX ID但是还没有到256的倍数,所以我们只要将其+256,就会得到一个唯一的事务ID咯。
trx_id隐藏列
我们在介绍数据行的时候就已经提到数据行的三个隐藏列
- row_id 就当我们没有主键或者unique列的时候,会生成一个这个唯一的row_id来保持记录的唯一性
- trx_id 事务ID
- roll_pointer 后面MVCC的时候介绍,这里链着一个版本链?
undo日志类型
为了保证原子性,所以Innodb对每个增删改都会在改之间进行一次undo日志的记录。
下面就来介绍一下增、删、改也就是insert、delete、update会产生的undo日志类型以及其细节吧。
INSERT的undo日志
我们使用insert的SQL语句时,就会产生一个TRX_UNDO_INSERT_REC类型的undo日志。

- end of record 和 start of record就是指向尾部和指向头部的地址。
- undo type 就是TRX_UNDO_INSERT_REC
- undo no 就是undo日志的no,对于每个事务来说这个值会从0开始,每个事务维护一个no从0开始慢慢+1递增。
- table id就是这个日志所在的表id
- 主键信息,多个列就是又多个<len,value>。len是主键占用空间的大小,value就是它的值。
所以innodb回滚会发生什么?首先呢,我们插入可能是悲观插入和乐观插入,悲观就是页满了得进行分裂,乐观就是没满直接将数据行插入。但是呢?innodb做的还是得到插入的主键值,然后删除主键值对应的聚簇索引和二级索引。
当我们执行insert插入时,插入的数据行中的隐藏列,我们关心的主要是事务ID和roll_pointer这两个属性。
- 因为我们执行的是插入,所以执行语句的事务会生成一个唯一的事务ID。后面我们将插入,修改,删除都会有一个唯一的事务ID,就不必多讲了。
- roll_pointer指向的就是innodb生成的undo日志。
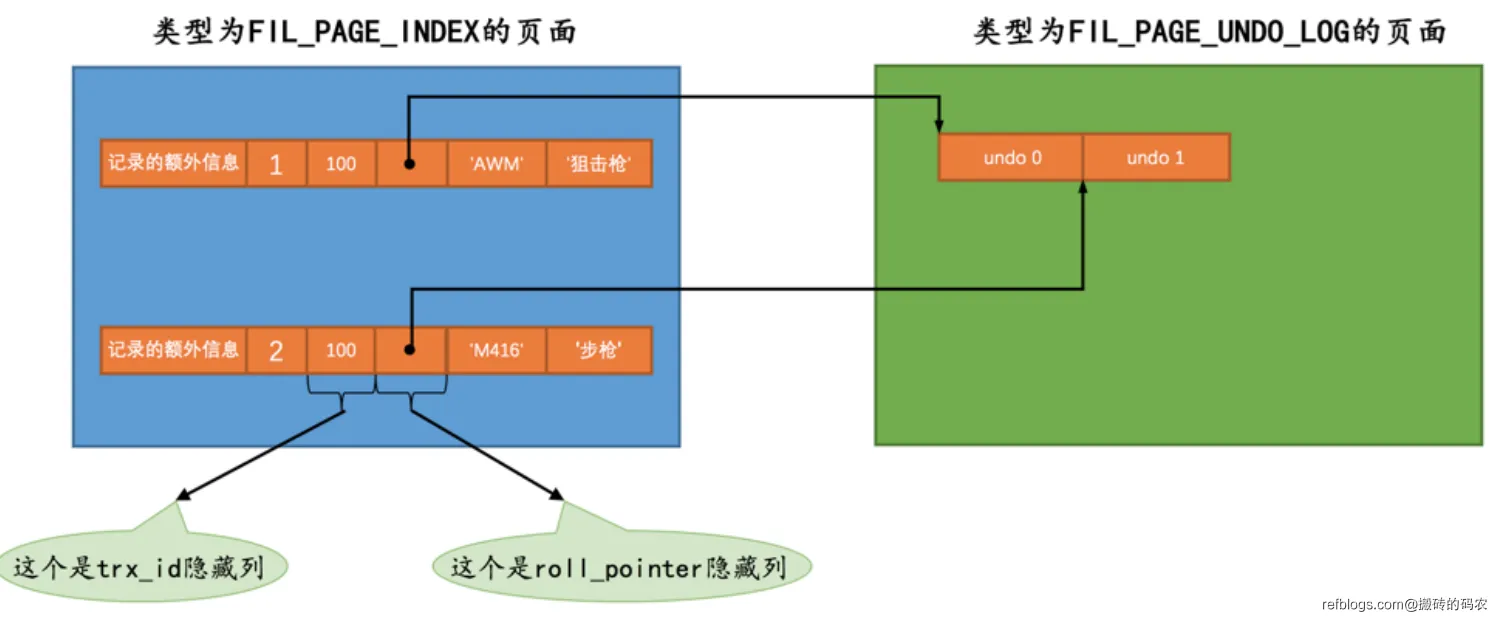
上图我们在一个事务中先后执行了2次插入操作,它的roll_pointer都指向了对应生成的undo日志。后续将介绍存储undo的页面。
DELETE的undo日志
delete操作就稍微有点特殊了。
我们在前面介绍页面的时候介绍了一个数据行的next_record属性,就是指向下一个数据行的指针。我们也说过这些被删除的数据行是可以被重用的,它其实是被一个存储在PAGE_HEADER中的一个PAGE_FREE的属性给链起来了,也就是说被删除的垃圾页面会形成一个链表。

我们在介绍数据行的时候也介绍了一个delete_mask位,用来标记数据行是否被删除。
在事务中呢,删除分为了两个阶段
- delete_mask变为1,但是却没有加入垃圾链表,成为了一个中间状态的行记录
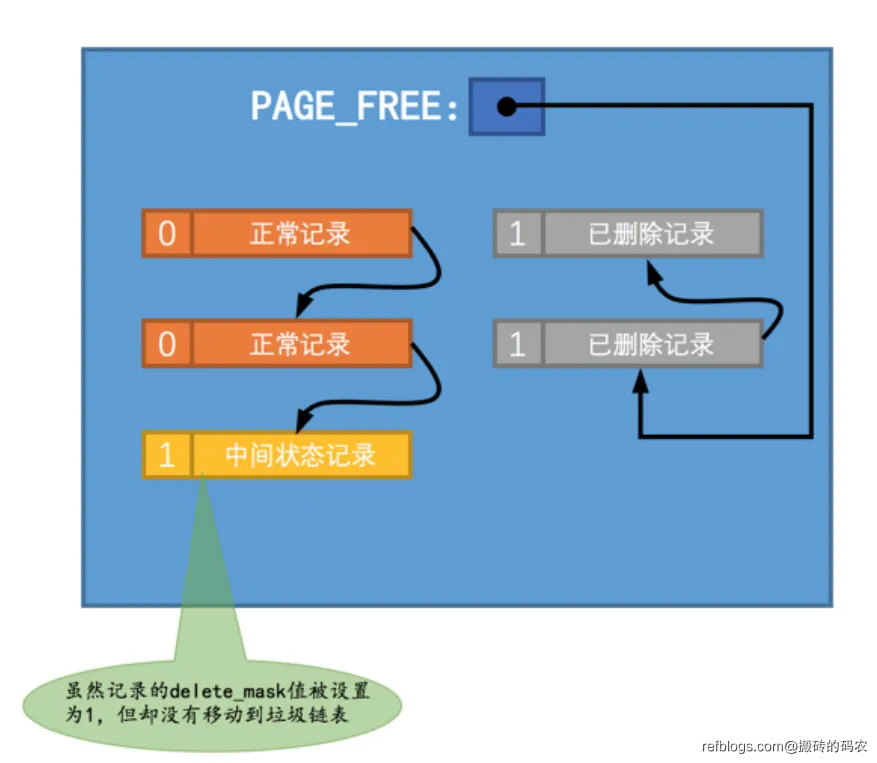
- 然后在执行该语句的事务提交的时候,会有专门的线程来将其放入垃圾链表中,然后修改页头中的记录信息。这个阶段称为purge。
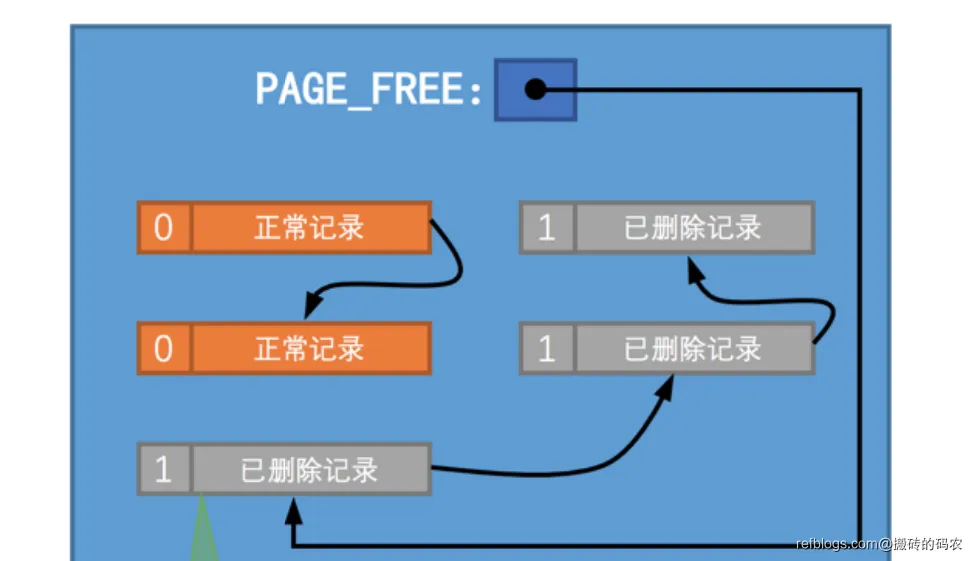
之所以有这个垃圾链表,就是为了让接下来插入的数据行用来重用的,如果不能用来重用,这个垃圾链表简直没有意义。
同时呢我们需要注意到,新删除的记录是放在垃圾链表的第一个的,可能是只有PAGE_FREE头部地址是被记录的,所以我们只能用头插法插入到链表中。
重用流程:
首先数据行要插入到页中,先检查垃圾链表头的大小是不是>=插入的数据行的大小,如果是就直接将垃圾链表头拉出来覆盖重用。否则就重新创建。
是没有错,它只检查垃圾链表头,其他的都不检查,而且容易出现碎片,因为是大于等于的条件进行重用。
当出现插入新记录时空间不足,检查垃圾链表的空间和碎片的空间够不够放下记录,够就会进行复制页面有用的数据,这是无可奈何之举,这样就可以去掉碎片和不可用的垃圾链表。
我们在改变中间状态时,会生成一个TRX_UNDO_DEL_MARK_REC类型的undo日志。

我们需要注意的是它将旧的事务ID和roll_pointer记录下来了,以及主键和索引列的信息。
所以会出现下图的情况,出现了一个版本链,原本是指向了插入的undo日志,然后删除的中间状态下,删除的undo日志还会指向插入的undo日志。

具体的删除undo日志就是如下

值得注意的就是索引列的各列信息<pos,len,value>,pos指向的是索引列在第几个列。
update的undo日志
update有两种情况
- 不更新主键
- 更新主键
不更新主键
如果更新的不是主键列。
旧记录 ("a","15")
新纪录 ("b","20") 大小没有发生改变
新纪录 ("aa0","20") 第一个列大小发生了改变- 当更新后的数据行每列的大小不发生改变,强调一下是每列的大小都不发生改变。我们就会使用就地更新,直接将更新后的数据行覆盖到旧的数据行。
- 当更新后的数据行列的大小发生改变,我们就不能就地更新。我们将使用用户线程去删除旧记录,即直接delete_mark置为1然后直接放进垃圾链表中,没有像delete语句那样还弄什么中间状态和调用其他线程去删除数据行。然后将新数据行加入到页中,同时如果小于垃圾链表第一个的大小还是重用删除页。
不更新主键的情况下会插入的undo日志如下:

更新主键
如果更新的是主键的话,我们的操作将完全不一样。
- 我们将记录直接将旧的数据行的delete_mark其标记成1,但不放入垃圾链表中的中间状态,然后插入类型为TRX_UNDO_DEL_MARK_REC的undo日志,在事务提交时就会有专门的线程做purge操作。
- 然后我们就可以直接将新的数据页插入到其中,然后插入类型为TRX_UNDO_INSERT_REC的undo记录,记录下旧的数据行的信息。
更新主键的情况下会产生2条undo日志。
为什么要这样呢?主要是因为如果我们在更新的时候,并发的事务要读取这条旧的数据,为了防止脏读,就需要将其置为中间状态,让其他事务同样也可以读到这条旧的数据。如果我们直接删除了其他事务就读不到了,不就脏读了嘛。
UNDO日志的存储
接下来就是介绍undo日志会存放在哪里了。。十分的枯燥,而且就到处引来引去。而且感觉讲得云里雾里
通用链表结构
这是链表中每个节点的结构,前面的页号+页面偏移量和后面的页号+页面偏移量

为了方便管理链表,就有了链表的基节点,指向首节点和尾节点,以及记录链表的长度。

链表本链在此。

FIL_PAGE_UNDO_LOG页面
我们前面在图片中出现了一次这个undo日志的存储页面。

我们接下来介绍一下这个undo日志的通用页面。File Header 和 File Trailer就不用介绍了吧,老演员了,和前面介绍的页面是一样的。
Undo Page Header

- TRX_UNDO_PAGE_TYEP 这个就是指什么种类的undo日志
我们在上面提到了增删改会产生的undo日志,其中呢,我们可以分成两个种类。
- TRX_UNDO_INSERT : 类型为TRX_UNDO_INSERT_REC的undo日志,一般在insert语句产生,还有就是update更新主键的时候
- TRX_UNDO_UPDATE : 除了TRX_UNDO_INSERT_REC类型的undo日志,其他类型都这个种类的。
- TRX_UNDO_PAGE_START 指的就是当前页面undo日志从哪里开始
- TRX_UNDO_PAGE_FREE 指的是当前页面空闲的地址。

- TRX_UNDO_PAGE_NODE 代表一个LIST NODE的结构,会有一个指向前后的指针。就是页面之间形成链表的结构。
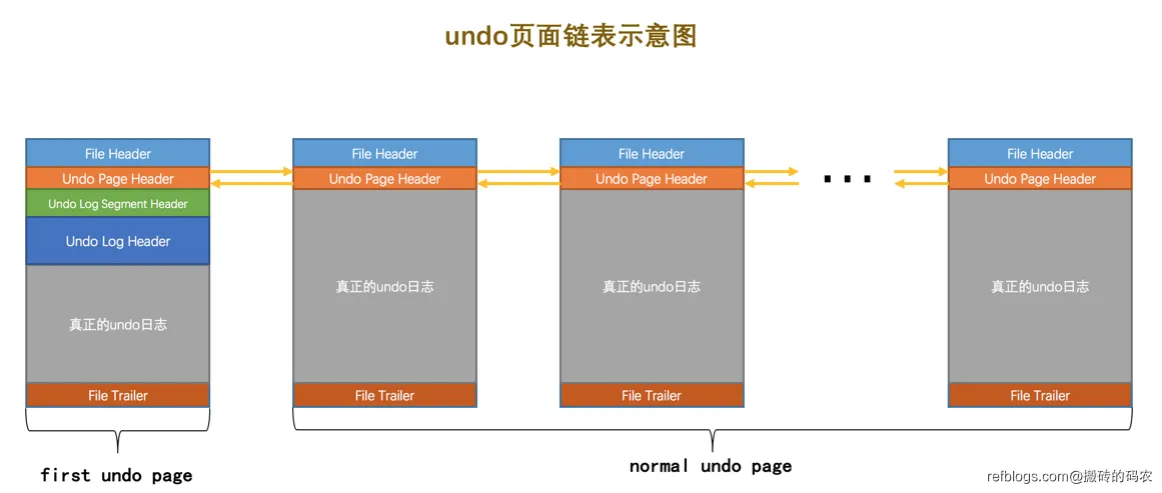
UNDO页面链表
当一个事务中,我们生成的undo日志过多了,一个页面肯定是放不下,我们就会创建多个页面进行存储,然后我们使用链表将其链起来。
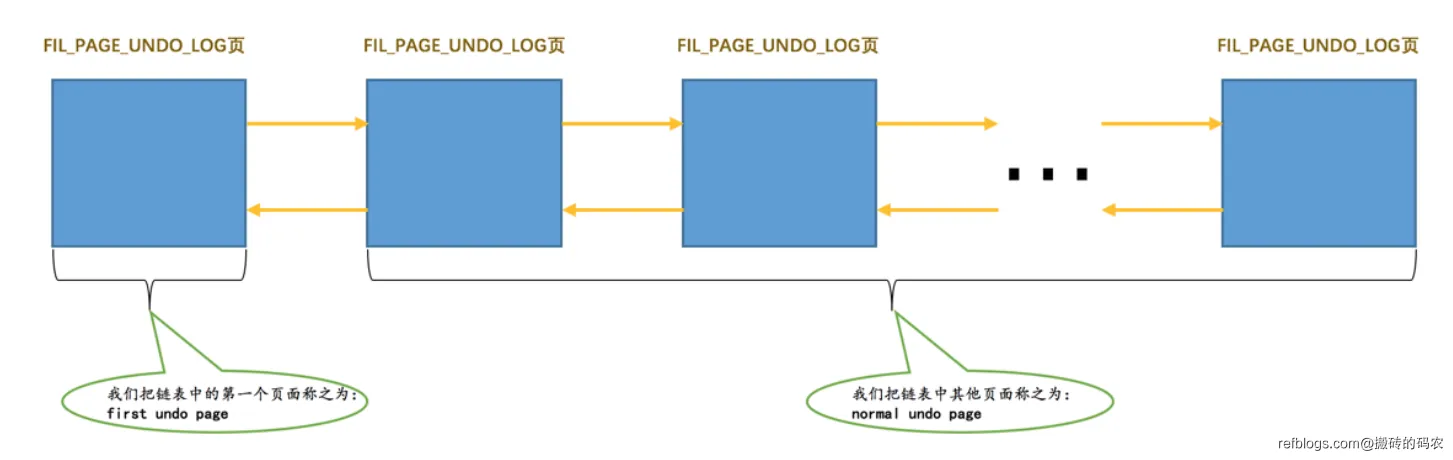
我们将undo页面链表的第一个页面叫做first undo page ,其他页面叫做normal undo page。
我们上面也提过的,就是我们可以将undo日志分成两个大类,一个是TRX_UNDO_INSERT 和TRX_UNDO_UPDATE ,不同种类的undo日志会存储到不同的undo页面中。所以呢,我们会为普通表和临时表各自维护这两个大类的页面。

但是呢,这个undo链表只有当前事务执行SQL创建了相应种类的undo日志我们才会去创建这个链表,并不是一开始就创建。
对于不同事务来说,不同事务有不同的undo页面链表。

段
我们前面讲过在B+树的根节点存储了Segment Header 结构,就是存储INODE ENTRY的位置。

Undo Log Segment Header
我们在上面提到的undo页面链表的结构,第一个undo页面我们叫做first undo page。
因为first undo page有点不一样,它被设计存储了一个Undo Log Segment Header 的部分,用来表示对应段的Segment Header信息以及关于段的其他信息。
说实话, 没懂这个结构有个dio用,就TRX_UNDO_LAST_LOG 在后面有点用,其他的都是一句就过了。

我们再来看看Undo Log Segment Header 里面存放了什么。

- TRX_UNDO_STATE 该undo页面俩表处于什么状态
- TRX_UNDO_ACTIVE 活跃状态,表示活跃事务正在写入undo日志
- TRX_UNDO_CACHED 缓存状态,表示该undo页面正在等待被其他事务重用。
- TRX_UNDO_TO_FREE 对于insert undo链表来说,如果在事务被提交时,此链表不能重用就会处于这个状态。
- TRX_UNDO_TO_PURGE 对于update undo链表来说,事务提交时,页面不能重用就会进入这个状态。
- TRX_UNDO_PREPARED 包含处于PREPARE阶段的事务产生的日志。分布式事务会出现该状态。
- TRX_UNDO_LAST_LOG 本Undo页面链表的最后一个Undo Log Header的位置。这个还好理解一点在看完全部章节之后,因为页面会重用嘛。
- TRX_UNDO_FSEG_HEADER 本Undo页面链表对应的段的Segment Header信息,一个undo链表也是被一个段维护起来了。
- TRX_UNDO_PAGE_LIST Undo页面链表的基节点
Undo Log Header
好乱真的无语,作者写的这章我真?了,我看了3遍都还不懂。上面那个结构完全不知道要干什么。
在Undo Log Segment Header下面存储了Undo Log Header块


重用undo页面
重用的条件
- 该链表中只包含一个Undo页面。
- 该Undo页面已经使用的空间小于整个页面空间的3/4
insert undo链表的重用,对于这个链表当满足上述两个条件时,会直接覆盖重用undo页面。因为插入旧的undo日志在事务提交后旧没有用了。

update undo链表的重用,对于这个链表满足上述两个条件时,会在旧的undo页面中的free处继续写。因为MVCC需要用到旧的undo日志的,是不能覆盖的。

回滚段
相当于将每个事务维护的first undo page给集合起来,放到一个页面中,这个页面就叫回滚段。

- TRX_RSEG_MAX_SIZE : 这个回滚段维护第一页链表中的undo页面的最大值。
- TRX_RSEG_HISTORY_SIZE : history链表的占用的页面数量
- TRX_RSEG_HISTORY : history链表的基节点
- TRX_RSEG_FSEG_HEADER : 回滚段对应的段的位置INODE Entry
- TRX_RSEG_UNDO_SLOTS : 各个first undo page 的位置的集合,也叫undo slot集合。
从回滚段中申请一个undo slot
undo slot 中的TRX_RSEG_UNDO_SLOTS 每4字节都是一个默认值FIL_NULL。
当事务需要创建一个undo链表,就会向回滚段申请一个undo slot。 回滚段就会顺序往下找,找到值为FIL_NULL的4字节地址,然后undo链表申请了第一个页面的地址放入到undo slot 中,就是将其地址改变为申请的页面的地址。
当事务提交时,我们需要判断这个slot是不是能被重用:
- 如果能重用根据其种类加入到insert undo cache或者update undo cache链表中。
- 如果不能重用呢
- 如果是种类insert种类的就会将其TRX_UNDO_STATE 设置为FREE的状态,这个页面就被释放掉了,该页面能作为其他的undo日志用。
- 如果种类是update的就会将其TRX_UNDO_STATE 设置为purge状态,然后这个undo链表头会被放到History链表中。不能删除因为MVCC要用。
多个回滚段
就是当事务多起来了,每个事务都由4个链表要维护,就要4个undo slot ,一个回滚段就不够,旧版本就一个回滚段。
所以就在系统表空间中申请了128个8字节的格子。


因为这个space ID就指表空间ID,Page Number就是对应表空间的页号。这个表空间ID就表示不同的回滚段可能位于不同的表空间中。这样我们就有128*1024个undo slot 可以分配使用了。

回滚段的分类
第0号,第33-127号回滚段属于第一类。第0号一定在系统表空间中,他们是针对普通表的undo slot 进行分配。
第1-32号回滚段属于第二类。是分配给临时表的undo slot。无论我们怎么修改回滚段的大小,这32个是一定在的。
在修改针对普通表的回滚段时,对于页面的修改是需要redo日志来记录的,而对于临时表的修改是不需要写redo日志的。
事务分配Undo页面链表过程
-
首先向系统表空间申请一个回滚段
回滚段是循环使用的,就是从0 、33-127这几个位置,就循环分配给事务,防止都分配一个回滚段炸了。
-
先从cache链表中找到对应类型的有没有可以重用的,有就直接将重用链表拿出来重用。没有下一步。
-
找到一个没被占用的undo slot ,将申请first undo page 位置填到对应的地方。
-
然后就可以插入undo日志了。
回滚段的配置
mysql> show variables like 'innodb_rollback_segments';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_rollback_segments | 128 |
+--------------------------+-------+
1 row in set, 1 warning (0.04 sec)我们可以修改回滚段的大小,但是不管多小临时表的32个回滚段都在的。
后面文章总结MVCC,这算是MVCC的一个前置知识。




